0%
Cronet同步模型异步请求分析与完善
1. 背景
在通过数据分析的过程中,发现我们在统计上无法统计到404的场景,透过数据去查问题,由于我们App使用OkHttp、Cronet的混合,通过动态调度来进行切换,这里主要是记录使用cronet遇到的问题。
2. Cronet使用模型
Android Cronet是异步网络库(Java封装层),请求是异步,结果通过回调的方式;但是官方基于异步模型封装了一个同步请求的,接下来我们来介绍这2种方式。
2.1 异步方式请求Cronet
先看下大致的异步请求代码:
1 |
|
以上代码就是cronet请求的样子,发起请求时,需要提供一个callback,这个callback,但是这个callback的触发不完全是被动,需要进行某些操作才能够触发。异步请求个人在实践过程中发现一个问题,这个问题就是在请求响应回来时,我们会对code进行判断,判断是否是http层成功(code==200),如果不是http层成功,比如4xx、5xx,那么我们就会回调一个error给上层的业务。
如下时序图:
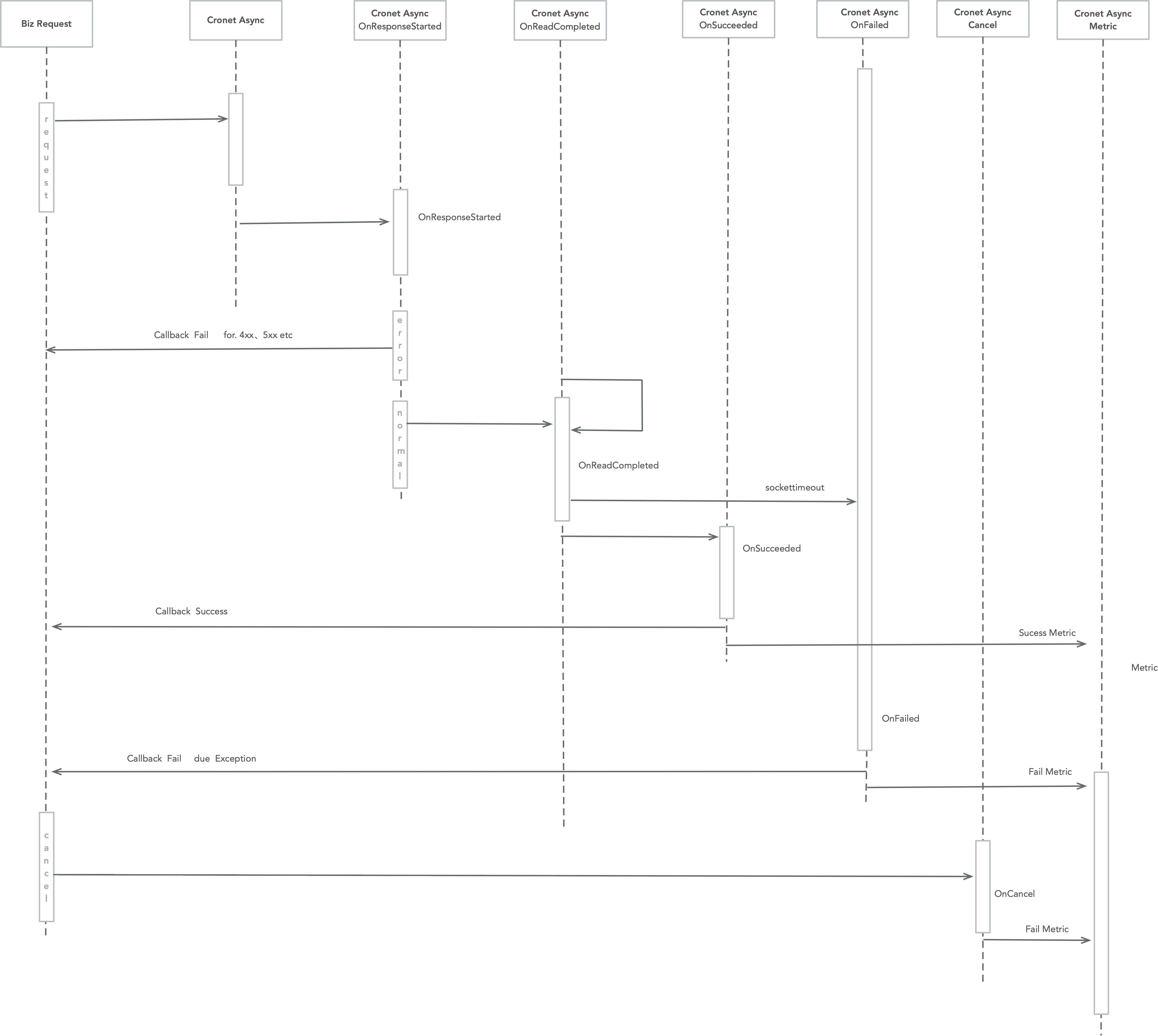
有如下的说明:
- 时序图中,onResponseStarted方法是已经响应处理的地方,如果这个时候判断code非成功(成功是200=<code<300),直接return,cronet底层的metric监控将不会回调
- 只有进行数据的读取操作,才会调用onReadCompleted、onSucceeded
- 连接、ssl、数据读取会产生异常
- 触发Metric监控的回调cronet内部产生了异常、进行了读取数据(成功、失败)、上层调用cancel
- Cronet面向Android的Java层api,没有提供close接口,只有cancel
网络底层统计逻辑,面对各种各样的请求,我们不能在面向业务回调的地方进行埋点,Cronet提供了一套完整的监控回调体系,如下:
1 | public abstract static class Listener { |
提供了一个抽象的类,来进行数据的收集,在上面的请求中的setRequestFinishedListener,我们可以针对每个请求加上监听回调。
所以在底层通过RequestFinishedListener来监听获取请求网络数据,需要解决异步回调处理非 200 响应code的问题,比如如下处理:
1 |
|
判断code是否是成功的http响应,不是的话就直接return,这样就会导致底层的监听没有回调,为啥没有回调?
- 能回调onResponseStarted方法,说明网络层tcp层是成功的,由于没有进行数据的读取,所以不会驱动onReadCompleted、onSucceeded的回调,所以也就没有回调Metric监听器
目前底层Metric监控的状态回调中有三种状态:
1 |
|
如果在这里判断http code来决定是否读取数据,会导致监控数据缺失,所以这处应该要调用release
或者 close 接口,但cronet 在java层并没有提供。
2.2 添加close接口
由于连接、ssl这块如果出现问题,会回调onFail,也会到底层Metric接口中,所有close只需要处理以下2种场景
- http层非成功的响应码(4xx、5xx这些)
- 同步请求中,读超时(http code 200)
3 同步请求
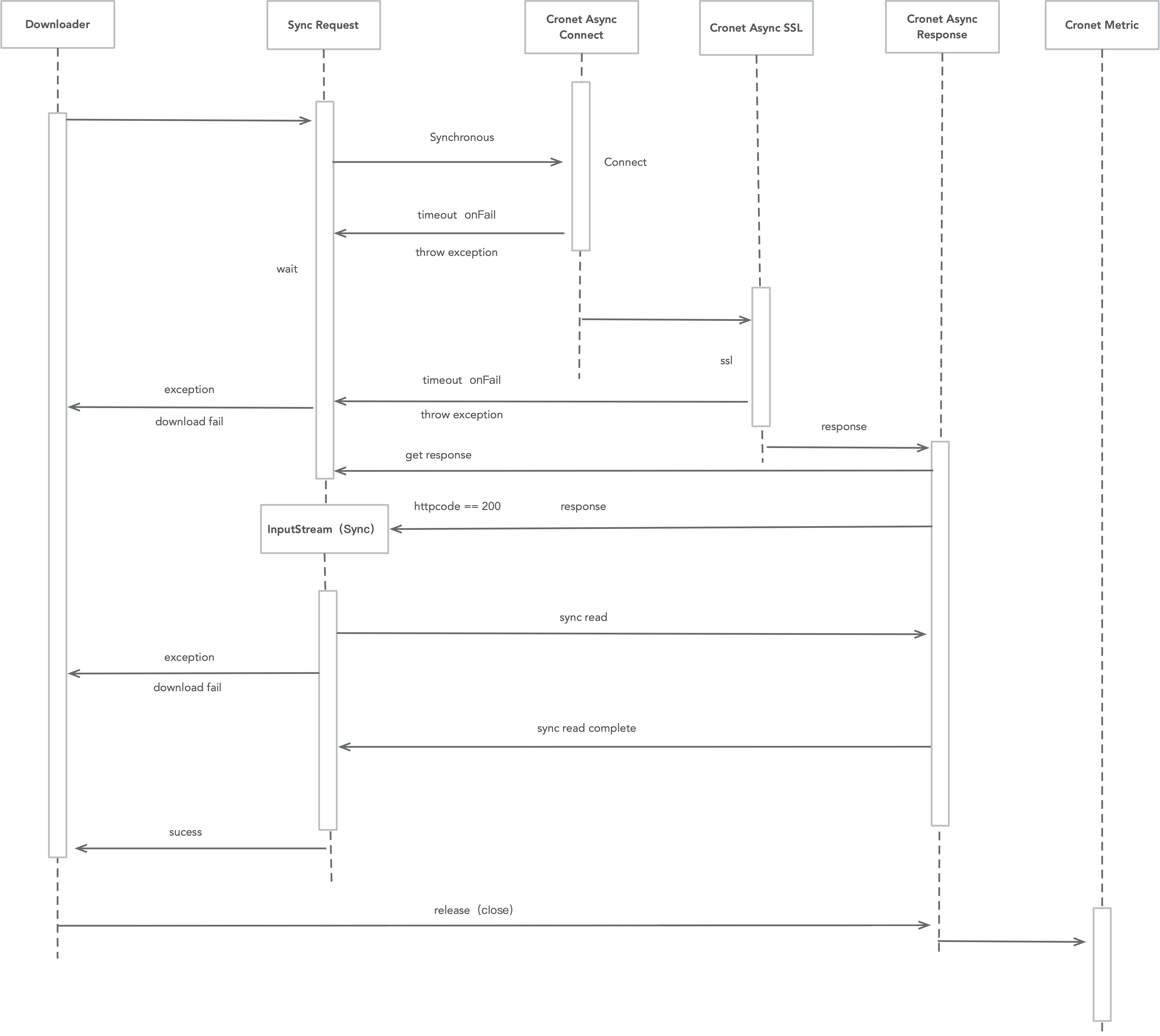
同步请求是使用UrlHttpConnection的接口来封装的,也就是同步调用的异步网络请求方式。
比如下载场景的,同步接口调用的时序图:
关于Activity使用SingleTask,从home点击图标后清空栈的问题
问题背景
如果从桌面启动的MainActivity的launchMode=SingleTask,那么当app调用其他的Activity时,用户回到home键回到桌面,再次进入App时,原来的界面会消失,直接显示在来MainActivity所在的页面
Activity的四种运行模式
Standard
- 默认模式,允许多个Activity实例
SingleTop
- 相比于
standard,有新的启动请求时,只有在目标Activity处于当前栈顶时,才会调用onNewIntent()而不创建新实例,其他情况都和standard一致
SingleTask
- 设置了
singleTask启动模式的Activity,它在启动的时候,会先在系统中查找属性值affinity等于它的属性值taskAffinity的任务存在;如果存在这样的任务,它就会在这个任务中启动,否则就会在新任务中启动。因此,如果我们想要设置了singleTask启动模式的Activity在新的任务中启动,就要为它设置一个独立的taskAffinity属性值。如果设置了singleTask启动模式的Activity不是在新的任务中启动时,它会在已有的任务中查看是否已经存在相应的Activity实例,如果存在,就会把位于这个Activity实例上面的Activity全部结束掉,即最终这个Activity实例会位于任务的堆栈顶端中。
SingleInstance
- 和
singleTask相比,不同点在于singleInstance activity所在的task只会有这一个activity
原理分析
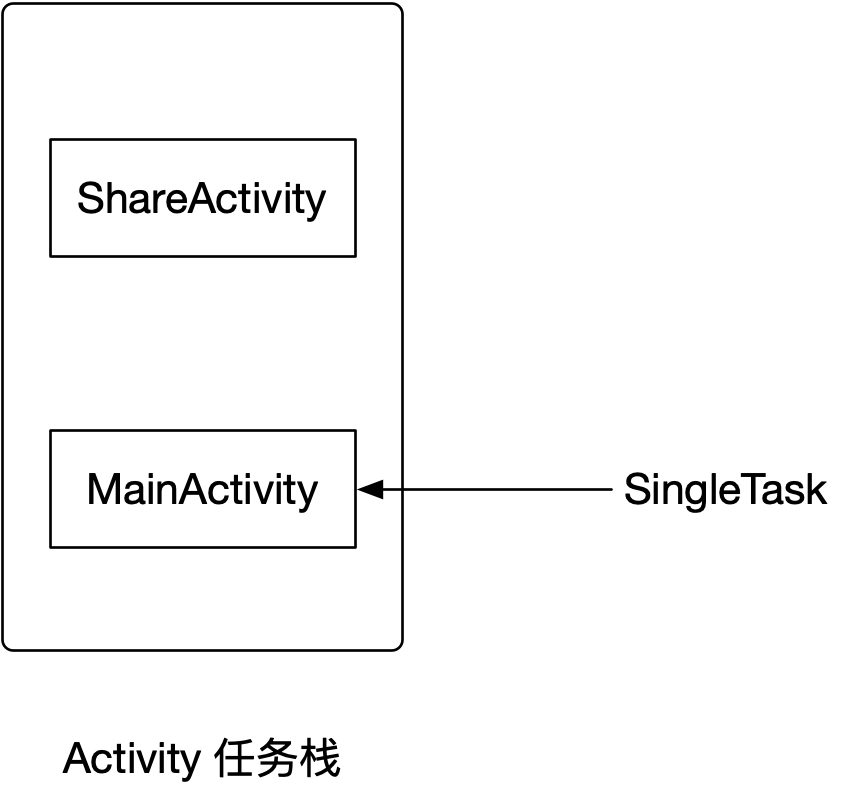
按照我们应用的启动流程,首先进入的是MainActivity,这个时候再次进入一个其他的Activity,那么我们回到用户桌面,再次进入App,这个流程图大致是:
start MainActivity -> 首页 -> 进入另外一个XActivity,从桌面进入App -> MainActivity
- 那么这个时候XActivity和MainActivity在同一个任务栈并且XActivity是在MainActivity之上
- 当我们再次从桌面进入App的时候,这个时候系统会调用Launch属性的MainActivity,
由于MainActivity是SingleTask会进行清除在其之上的Activity,将自己置于栈顶
所以我们再次进入App后,原先进入的Activity页面不见了而显示了首页,就是因为MainActivity的SingleTask会进行清除其之上的Activity
解决办法
双Activity
- 将LaunchActivity用做桥梁的作用,启动后将自己finish,每次启动App的时候LaunchActivity都是处于栈顶,而不是直接startMainActivity
ADB Dump 内存,Mat分析
ADB 命令DUMP内存,一般我自己的操作是,先通过adb命令dump内存信息到data/local/tmp/ 目录下,具体的操作是:
1 | adb shell am dumpheap com.yy.hiyo /data/local/tmp/xxx.hprof |
这样就在文件目录生成了对应的dump文件,然后通过AndroidStudio的DeviceFileExplorer来导出对应的文件,导出后要通过hprof-conv来转换
1 | hprof-conv source.hprof target.hprof |
然后通过MAT打开就可以了
Message、Handler、MessageQueue、Looper关系
背景
最近手头上有一些面试的任务,这个问题就是我比较常问面试者的问题,Android设计这样一个东西,理解源码后才能理解,才能更好的帮助我们进行更高层次的开发。所以就自己整理下,把阅读源码的思路记录下来。
类图结构
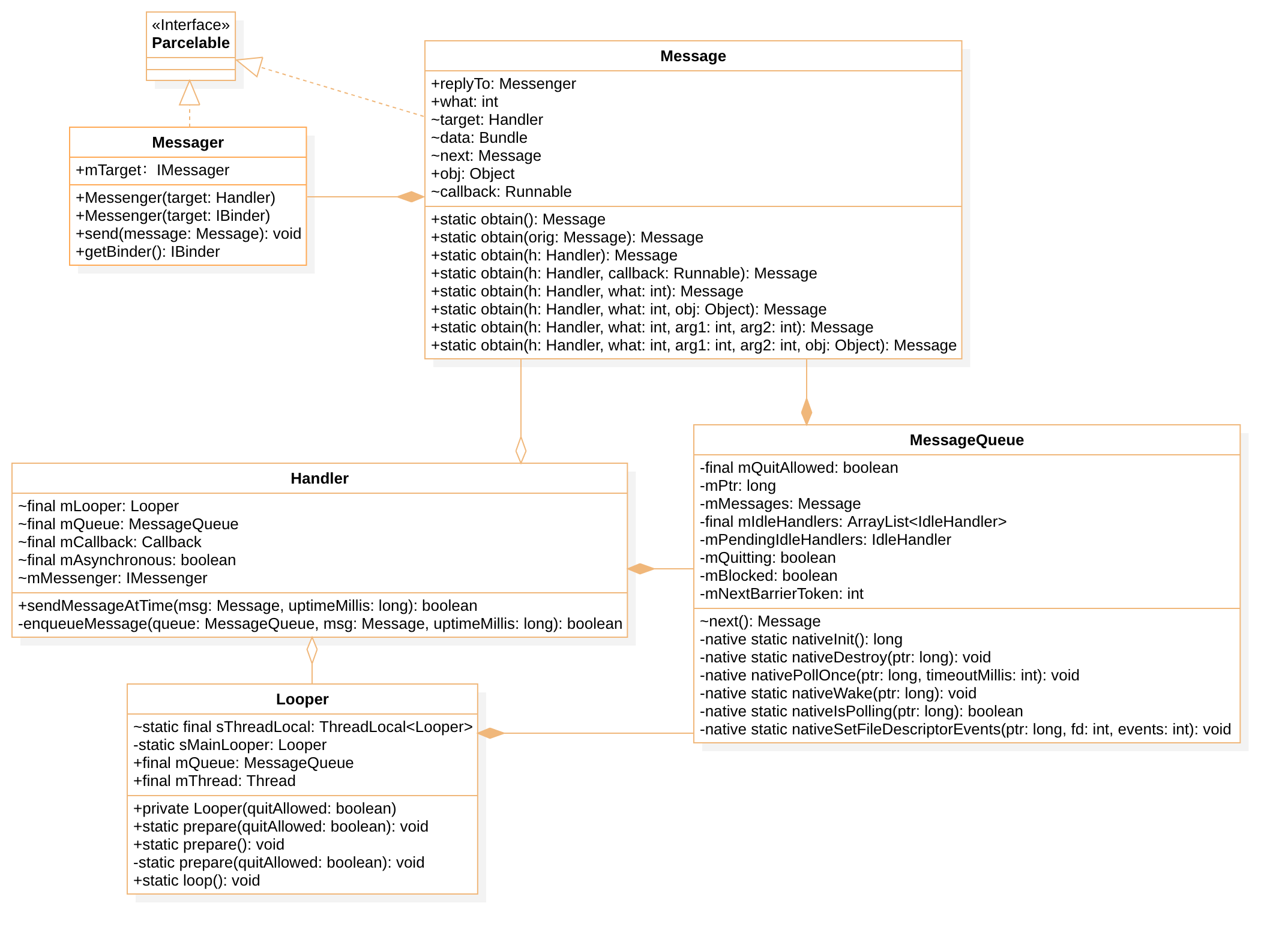
用一句话概括:
Handler把Message放入到一个Looper的MessageQueue中,我们用Looper.prepare() 准备一个当前线程的Looper,然后通过Looper.loop()进行消息循环,Looper.loop()方法中会通过MessageQueue.next()来进行消息的获取,如果没有消息就会阻塞
Message
Message实现了Parcelable接口,所以Message是可以进行跨进程传输的,但是需要注意obj,这个obj也必须需要实现Parcelable,否则会抛异常。
1 | public void writeToParcel(Parcel dest, int flags) { |
Message 中有一个Messager 可以接收方用来回信的,比较少用。 Message本身功能很简单,维护了一个MAX_POOL_SIZE=50的链表池,用来复用的,这是每个进程的,也就是每个进行都维护了长度为50的池子。
Handler
Handler的结构是很简单的,基本也没有做啥,都是一些封装,屏蔽了MessageQueue的细节。提供了post和send Message,同时提供了Message obtain Handler,Message的target就是Handler,这个Message的target最终是有Looper拿到Message后,通过target来调用Handler的 dispatchMessage(Message msg),Handler中有一个mAsynchronous变量,这个我们最后来说说异步消息是干什么的
我们看看这个方法:
1 |
|
这个方法比较有趣:
- 如果构造的Message中设置了Runnable的callback,会直接调用run方法,这个时候并不会执行handleMessage
- mCallback 是一个接口,这个接口是通过Handler的构造方法来传入,如果设置这个方法并且接口实现返回True,那Handler自身的方法handleMessage是不会掉用的
- 如果Message的callback 没有设置 并且 mCallback为null,或者mCallback的handleMessage返回false,Handler本身的handleMessage才会执行
所以Handler只是一个包装者,最后通过当前的线程的Looper把Message交给接受者处理。
接下来我们先看看Looper
Looper
从类图的结构来看,Looper向外部暴露的方法都是静态的,那么怎么为不同的线程提供Looper环境呢?
关键的是在ThreadLocal
当在不同的线程开启loop()后,我们看看源码
1 | public static void loop() { |
从源码来看,loop这个静态方法会调用myLooper,这个方法会取出当前线程的Looper,然后loop方法通过looper获取到MessageQueue,通过MessageQueue的next来获取消息Message,如果没有消息就会block,如果有消息,然后会调用
1 | msg.target.dispatchMessage(msg); |
target 是Message绑定的Handler,然后调用Handler中的dispathMessage,这样就进入到消息的分发。
Looper逻辑本身也比较简单:
- 通过Looper.prepare()来准备当前线程的Looper,保存在sThreadLocal中,如下的源码:
1 | public static void prepare() { |
- 然后通过Looper.loop()来进行消息循环,loop方法中会获取当前线程的Looper,所以Handler是一定需要Looper。平常我们在主线程可以直接创建一个不带Looper的Handler是因为主线程已经帮我们创建好了Looper,我们看看ActivityThread中的main方法
1 | public static void main(String[] args) { |
Looper 中
1 | public static void prepareMainLooper() { |
所以我们在ActivityThread中已经在主线程中创建了MainLooper了。
MessageQueue
先提一个问题:发送Handler是如何做到发送延时消息线程有不阻塞的呢?
从类图中,我们可以看到MessageQueue中有一个Message
1 | Message mMessages; |
我们能够知道MessageQueue是通过Message的next变量来进行链式结构,我们看看Message怎么加入到MessageQueue的,看看源码的方法
1 | boolean enqueueMessage(Message msg, long when) { |
Handler中最终都是通过这个方法来入队消息,这个方法主要做的事情就是找到当前入队msg在链式结构的合适位置,如果当前msg位于对头并且被阻塞就唤醒。这个是将消息放入链式中,然后通过条件要不要唤醒,如果唤醒Looper中的loop就会取消息,这个时候就会到MessageQueue的next方法来拿消息,如下源码:
1 | Message next() { |
后续继续分析如下的问题:
- 异步消息的作用,解决了什么问题
- Looper会无限循环,没有消息会休眠,为啥不会ANR,其机制和原理是怎么样的,
- Android主线程是何时创建的
TCP协议的三次握手和四次挥手
背景
最近一直在搞网络优化这块的事情,顺便花时间重新捋捋TCP相关的东西。
TCP三次握手
用一张交流的图,如图:
- 先询问能听到我说话吗
- 接收方听到后,需要进行回复
- 发送方收到接收方的回复后,需要进行确认,让接收方知道我听到你说话了,我们可以进行交流了。
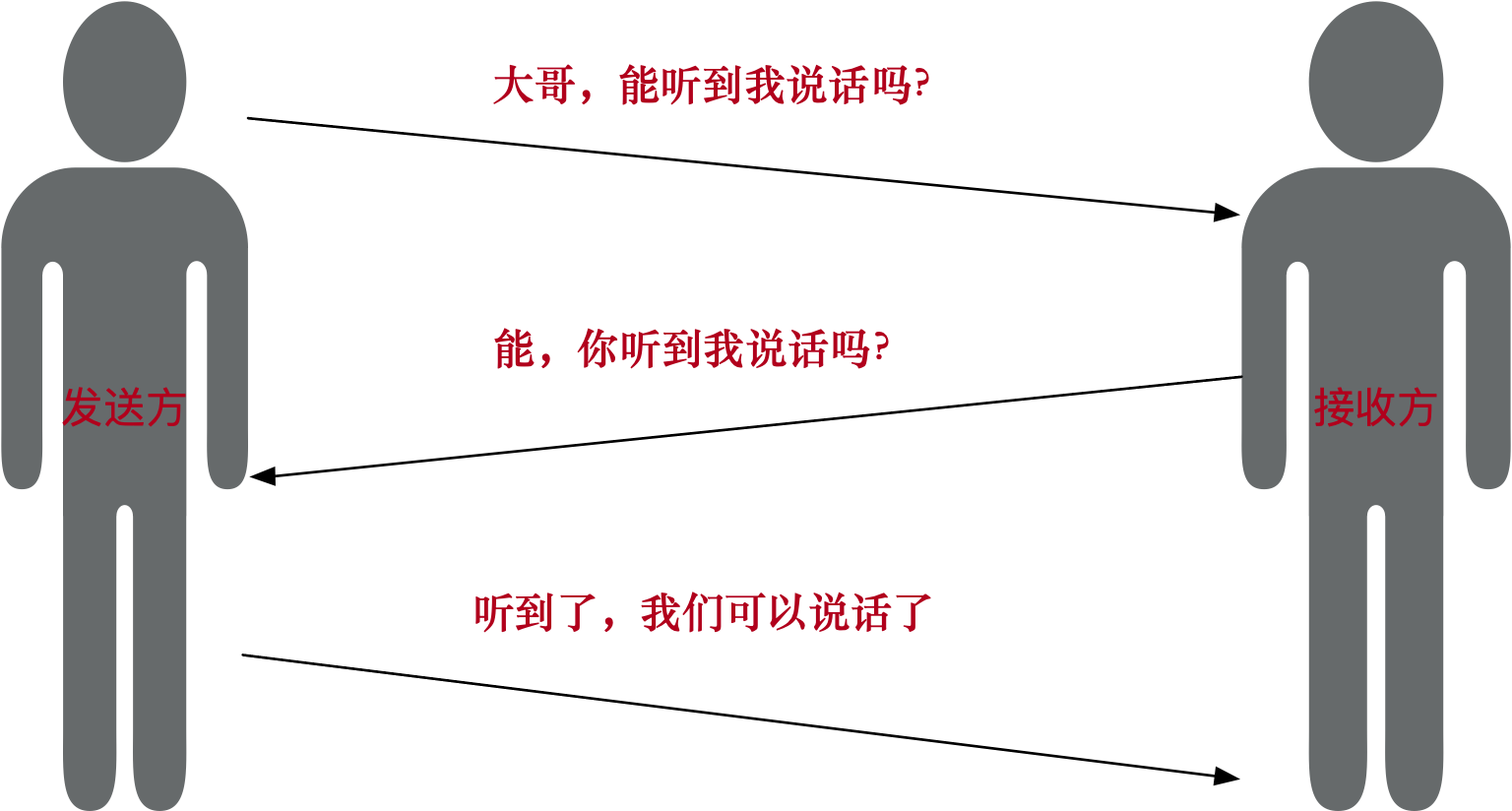
三次握手的数据交换
TCP数据格式

这里我们关注Syn、Sequence Number、Acknowledgment Number、Ack、Fin
ACK : TCP协议规定,只有ACK=1时有效,也规定连接建立后所有发送的报文的ACK必须为1
SYN(SYNchronization) : 在连接建立时用来同步序号。当SYN=1而ACK=0时,表明这是一个连接请求报文。对方若同意建立连接,则应在响应报文中使SYN=1和ACK=1. 因此, SYN置1就表示这是一个连接请求或连接接受报文。
FIN (finis):即完,终结的意思, 用来释放一个连接。当 FIN = 1 时,表明此报文段的发送方的数据已经发送完毕,并要求释放连接。
注意图中的ACK是表示Acknowledgment Number
握手图
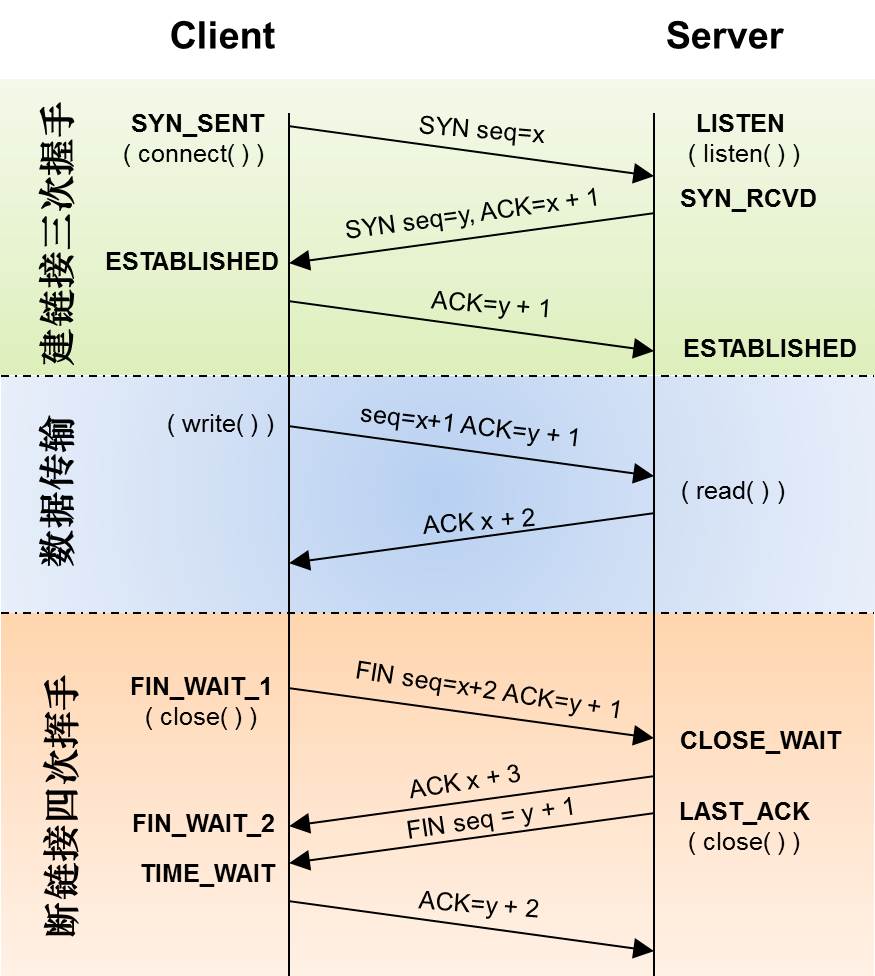
- 第一次握手:建立连接。客户端发送连接请求报文段,将SYN位置为1,ACK为0,Sequence Number为x,通过抓包发现这个值为0;然后,客户端进入SYN_SEND状态,等待服务器的确认;
- 第二次握手:服务器收到SYN报文段。服务器收到客户端的SYN报文段,需要对这个SYN报文段进行确认,设置Acknowledgment Number为x+1(Sequence Number+1);同时,自己自己还要发送SYN请求信息,将SYN位置为1,Sequence Number为y;服务器端将上述所有信息放到一个报文段(即SYN+ACK报文段)中,一并发送给客户端,此时服务器进入SYN_RECV状态,此后的阶段ACK的值都为1;
- 第三次握手:客户端收到服务器的SYN+ACK报文段。然后将Acknowledgment Number设置为y+1,向服务器发送ACK报文段,这个报文段发送完毕以后,客户端和服务器端都进入ESTABLISHED状态,完成TCP三次握手。
完成了三次握手,客户端和服务器端就可以开始传送数据。以上就是TCP三次握手的总体介绍。
四次挥手
当客户端和服务器通过三次握手建立了TCP连接以后,当数据传送完毕,肯定是要断开TCP连接的啊。那对于TCP的断开连接,这里就有了神秘的“四次分手”。
- 第一次分手:主机1(可以使客户端,也可以是服务器端),设置Sequence Number和Acknowledgment Number,向主机2发送一个FIN报文段;此时,主机1进入FIN_WAIT_1状态;这表示主机1没有数据要发送给主机2了;
- 第二次分手:主机2收到了主机1发送的FIN报文段,向主机1回一个ACK报文段,Acknowledgment Number为Sequence Number加1;主机1进入FIN_WAIT_2状态;主机2告诉主机1,我“同意”你的关闭请求;
- 第三次分手:主机2向主机1发送FIN报文段,请求关闭连接,同时主机2进入LAST_ACK状态;
- 第四次分手:主机1收到主机2发送的FIN报文段,向主机2发送ACK报文段,然后主机1进入TIME_WAIT状态;主机2收到主机1的ACK报文段以后,就关闭连接;此时,主机1等待2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,主机1也可以关闭连接了。