QuarkDownloader 读写分离原型
VandaDownloader开源
基于独立设计的浏览器下载原型的特性,重新设计、重构代码结构,使用Kotlin重新编写,开源地址:
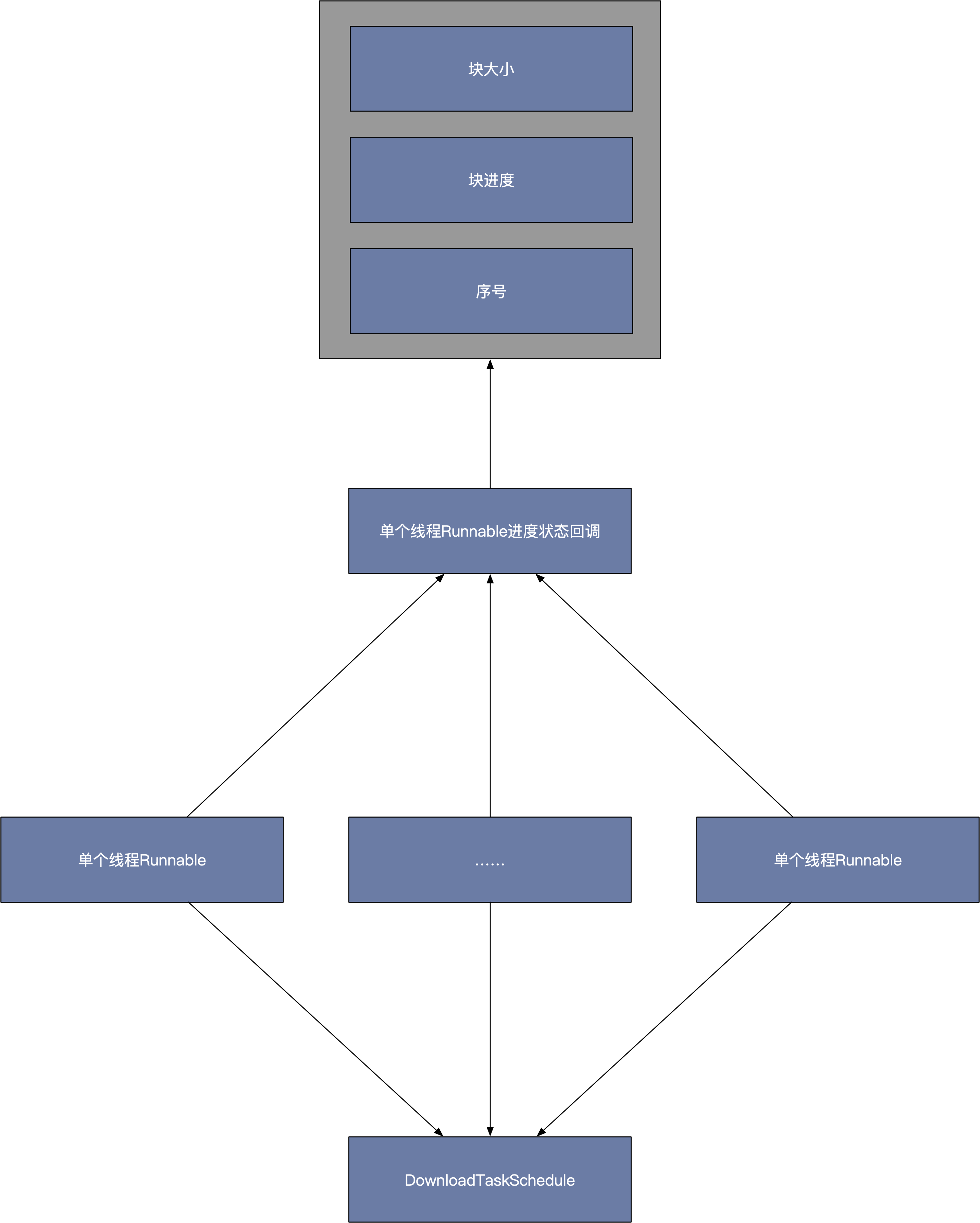
简易流程图
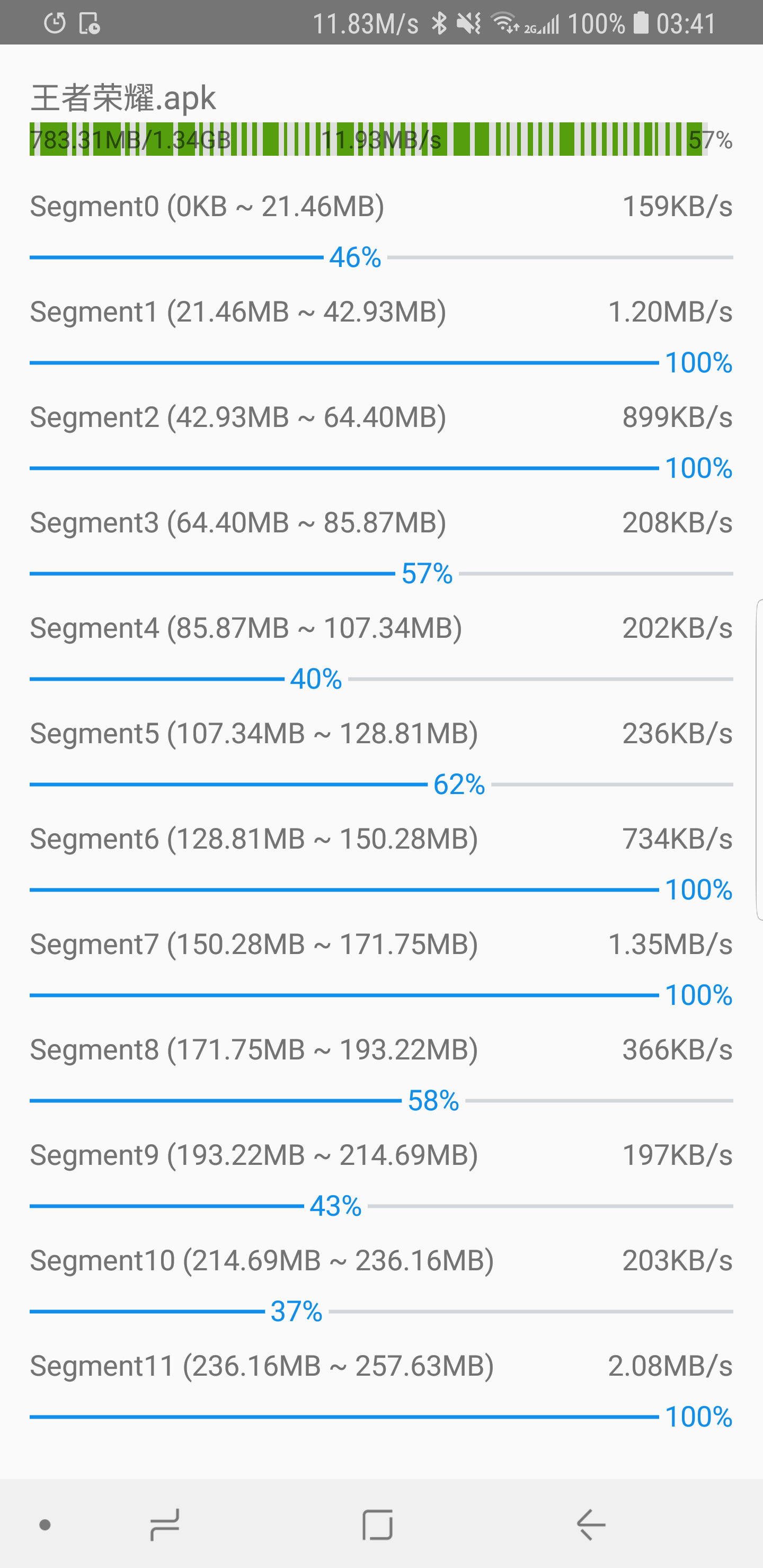
Demo
常规下载 & 读写分离
常见的文件下载手段其中一项是读写分离,也就是说利用空间换时间的方式来增加效率。
常规下载
一般来说,常见的文件下载方式如下:
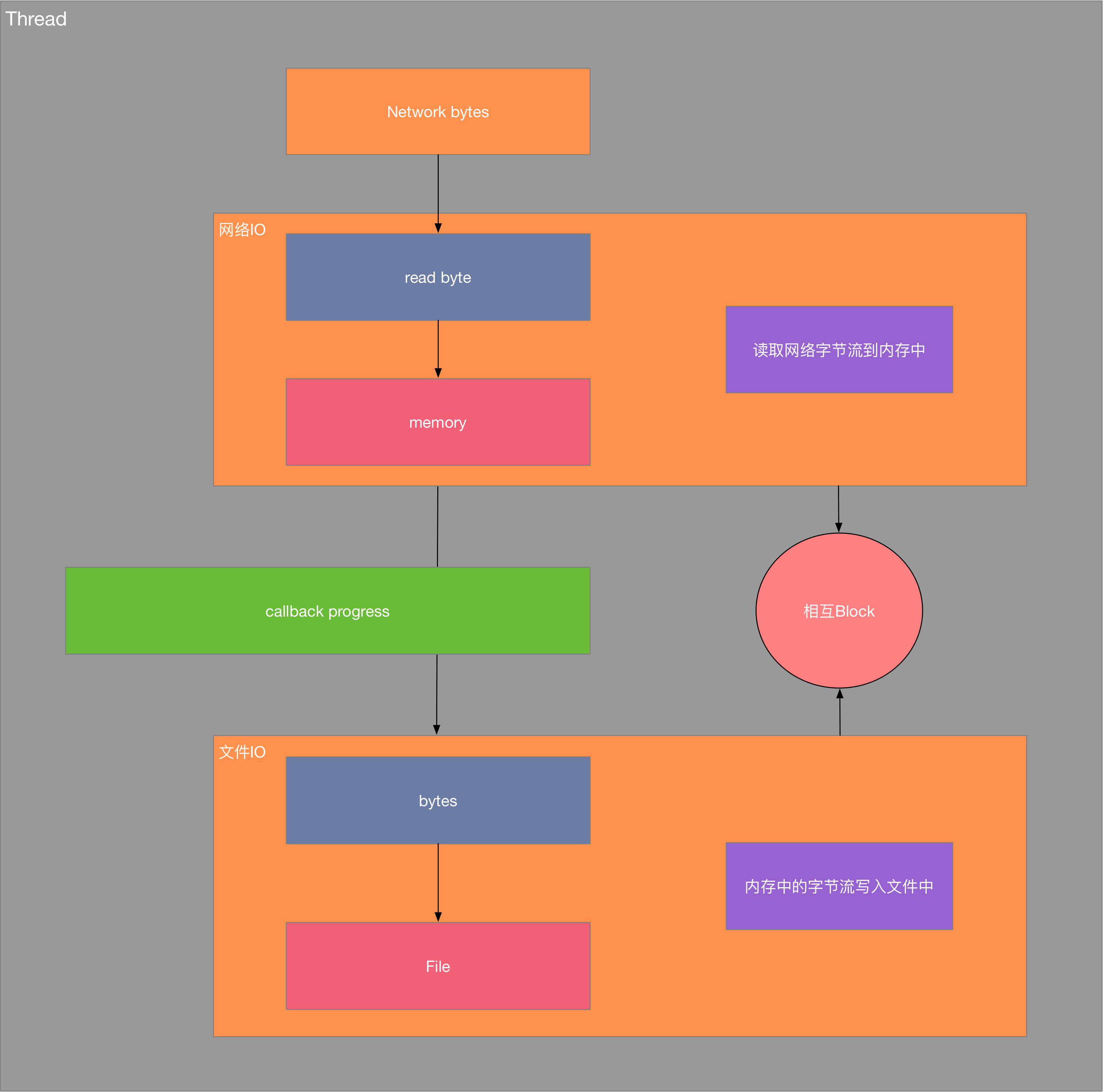
这种文件的下载方式也是我们常见的简单的文件下载,其中存在一些不足,
- 单线程进行文件的下载
- 网络IO和文件IO处于同一线程中,进行网络数据读取时,文件IO就处于block状态,进行文件IO时网络IO处于block状态,时间利用不高效
- 下载状态的回调也不应该有频繁的线程切换,回调不应该是文件下载线程直接进行回调
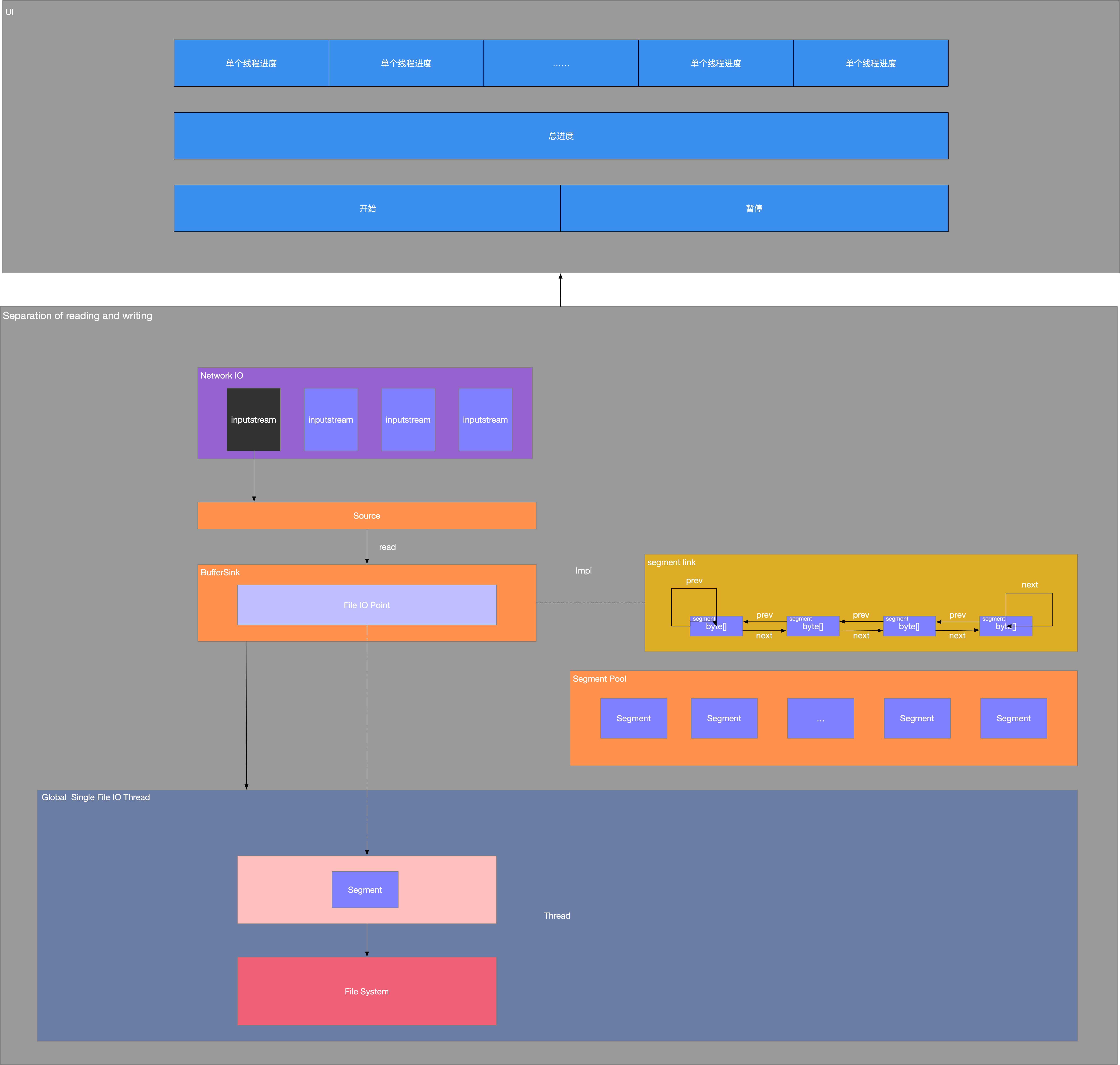
读写分离
读写分离的大致模型如下:
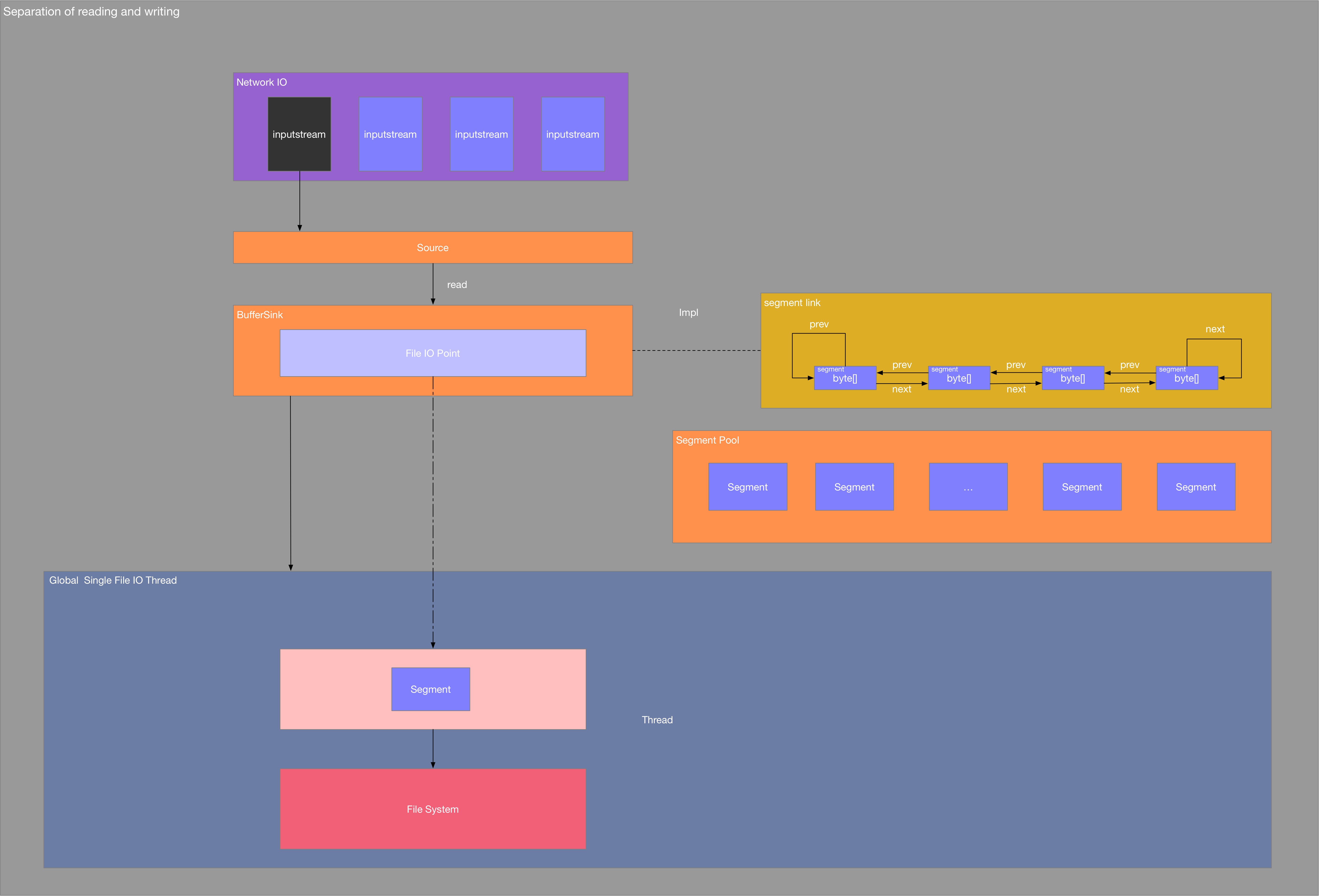
读写分离的主要目的有几点:
- 网络IO与文件IO相互不影响,不会block,当前线程负责网络数据的读取,没有文件IO的操作,当前线程网络数据读取就是最高效的
- 文件IO全局采用单个线程,避免了系统资源的浪费,同时避免了多个线程同时进行IO是操作系统调度带来的资源竞争。
- 每次读取segment时可以提供任务进度回调,而这个时候并没有进行文件IO操作,我们把数据保存在内存中
segment是一个双向链式结构,并且提供SegmentPool来缓存segment,避免系统GC和申请byte时的zero-fill。,这些数据块使用链表进行管理,这可以仅通过移动“指针”就进行数据的管理,而不用真正去处理数据,而且对扩容来说也十分方便。它对数据进行了分块处理,这样在大数据IO的时候可以以块为单位进行IO,这可以提高IO的吞吐率。